2026/5/21 11:59:16
网站建设
项目流程
网站的通栏怎么做,系统优化的意义,站长之家查询网站,品牌seo推广咨询# LLaMA-Factory 答疑系列二#xff1a;高频问题 官方解决方案#xff0c;建议收藏备用作为当下热门的大模型微调工具#xff0c;LLaMA-Factory 凭借灵活的适配性和高效的训练能力#xff0c;成为不少开发者的首选。因此#xff0c;我们联合**LLaMA-Factory作者郑耀威博士…# LLaMA-Factory 答疑系列二高频问题 官方解决方案建议收藏备用作为当下热门的大模型微调工具LLaMA-Factory 凭借灵活的适配性和高效的训练能力成为不少开发者的首选。因此我们联合**LLaMA-Factory作者郑耀威博士**亲自开设了 **《从零开始玩转LLaMA-Factory大模型微调》课程。别让明天的你后悔今天没点开这篇文章LLaMA-Factory作者亲授带你抢占AI微调先机** 课程上线后备受关注有不少开发者和在校生报名参与学习。在这个过程中我们收集了不少学院反馈过来的问题比如显存溢出、微调效果不佳、训练卡住等问题却频繁出现。**上一期我们整理了LLaMA-Factory 使用过程中的高频问题**,今天继续整理《从零开始玩转LLaMA-Factory大模型微调》课程中的高频问题附上官方认证的解决方案不管你是刚入门的新手还是有一定经验的开发者都能快速找到答案少走弯路## Q1我同时在大模型实验室平台申请多台算力服务器那么这些算力服务器之间可以进行通信吗A支持的。您可以通过命令cat/etc/hosts 来查看ip然后在另一个实例通过ip进行分布式推理或者训练。另外我们的基础设施是3.6TMbps的IB网络默认已开启IB网络网卡。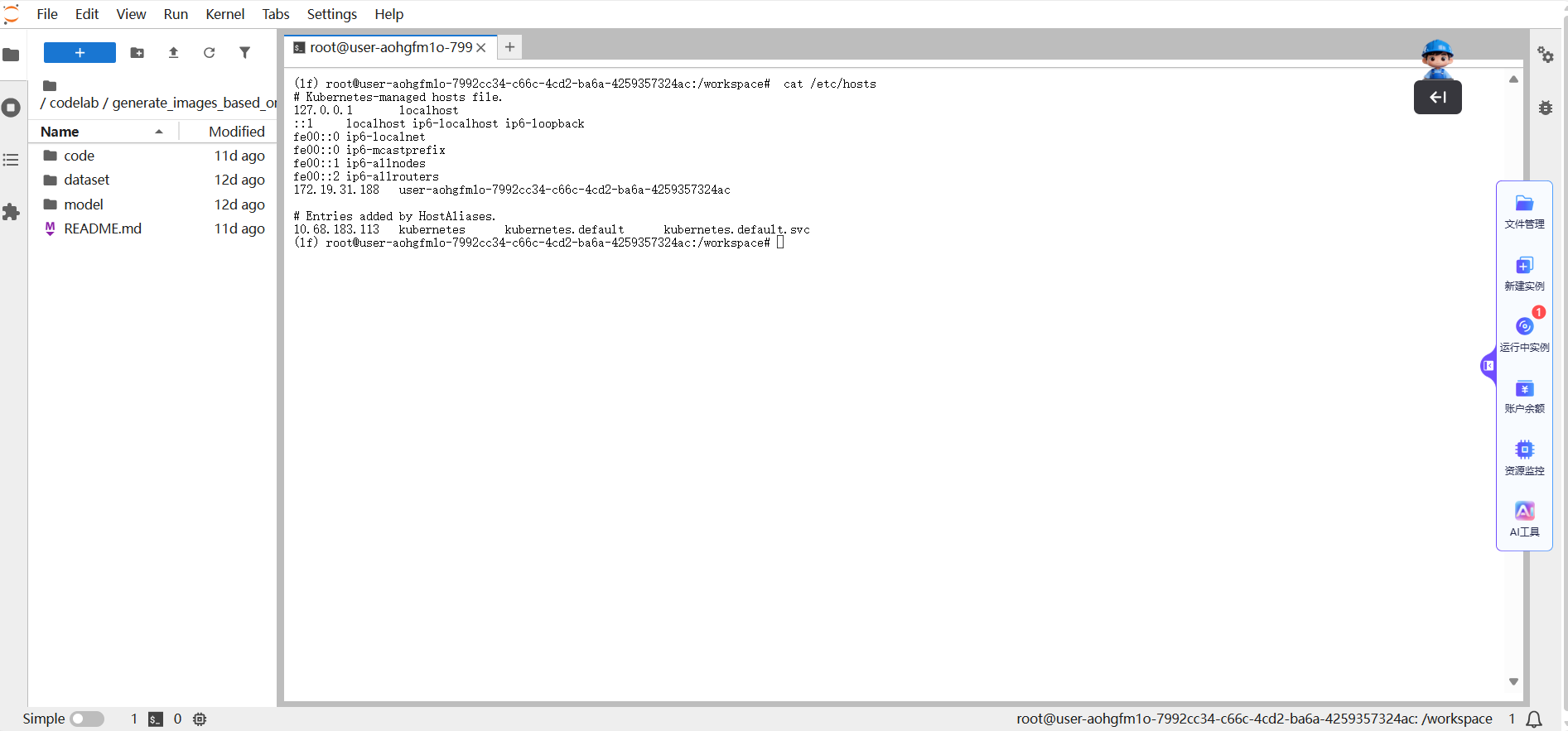## Q2如何学术资源加速A用户可通过以下网站对文件进行加速代理1**Github** 平台已内置了GitHub加速服务。您在执行Git相关命令时将自动享受更快的访问与下载速度。2**HuggingFace镜像站** 平台已内置HuggingFace加速功能。您只需正常执行下载命令系统将自动为您提速无需额外配置。HuggingFace下载的模型占用系统盘空间很大导致系统盘空间不够。默认HuggingFace的缓存模型会保存在/workspace/huggingface目录可以将模型的缓存保存到文件存储的盘具体操作如下2.1运行如下命令使用清华大学PyPI镜像源安装Hugging Face官方的Python SDK huggingface_hub以加速依赖下载。textpip install huggingface_hub -i https://pypi.tuna.tsinghua.edu.cn/simple2.2运行以下命令使用Hugging Face命令行工具huggingface-cli从指定仓库下载所需模型至指定路径。以下示例演示如何下载Qwen/Qwen2.5-1.5B-Instruct模型并保存到本地目录。texthuggingface-cli download --resume-download Qwen/Qwen2.5-1.5B-Instruct --local-dir Qwen/Qwen2.5-1.5B-Instruct## Q3为什么预训练样本数比实际的少A: 有用户反馈LLaMA-Factory 预训练时日志或界面显示的样本数量比实际准备的训练样本数更少担心数据未被充分利用。这是预训练阶段的默认优化机制 —— 自动启用了 Packing样本打包 功能。该机制会将多个短文本样本按模型支持的最大序列长度如 cutoff_len打包成一条长序列进行训练既避免了短样本导致的显存浪费又能提升训练效率。因此显示的 “打包后序列数” 会少于实际原始样本数并非数据丢失不影响训练效果。## Q4模型微调界面3个Job都是用 Lora 微调但是 Lora 的 lora_alpha 参数选不同为什么 trainable 的参数大小都是一样的呢 Alora_alpha的核心作用是调节参数更新幅度稳定训练过程而可训练参数量由 LoRA 秩 r 唯一决定因此不同 lora_alpha 对应的可训练参数大小完全一致。## Q5基于Qwen3-8B-Base 模型训练时GPU 显存使用率随训练进程持续上升最终因显存耗尽触发 OOMOut Of Memory错误疑问该现象是否为内存泄漏我该如何解决A观察到的GPU 内存增长是深度学习训练中的正常行为源于框架的内存优化策略缓存并非程序漏洞内存泄漏。如果训练能够长时间稳定运行而不崩溃即使内存使用率较高也通常是正常的。如果确实很快出现 OOM则应考虑调整模型或训练参数。实际应对措施接受这种内存增长行为只要训练稳定即可。如果遇到 OOM优先考虑调整以下参数来降低内存消耗- 减小 per_device_train_batch_size批量大小。- 减小 Cutoff length。- 使用梯度累积来模拟更大的批量大小。- 启用梯度检查点一种时间换空间的技术。- 考虑使用 deepspeed等更高效的内存优化工具。## Q6训练VL多模态模型如 Qwen3-VL、InternVL 等时数据集同时包含纯文本样本和多模态图文样本不清楚纯文本样本该如何格式化才能与多模态样本兼容A纯文本样本需遵循多模态数据的统一格式规范无需单独定义新格式仅将“images” 字段显式留空即可不可删除该字段。## Q7jupyter中checkpoints文件夹打不开也无法删除或者重命名终端可以正常操作AJupyter 中.ipynb_checkpoints 文件夹无法在 Web 界面操作是因为它是 Jupyter 自动管理的系统目录Web 界面对其进行了保护。解决方案包括终端直接操作删除 / 重命名、修改 Jupyter 配置自定义检查点位置或禁用自动检查点。操作前需注意备份当前 Notebook 内容避免丢失重要数据。## Q8训练数据是否会自动随机打乱若需固定数据顺序该如何操作ALLaMA-Factory 训练时默认会对训练数据进行随机打乱。关闭打乱方法若需固定数据顺序如时序类任务、特定顺序训练场景直接在训练配置文件中添加参数disable_shuffling: true 即可关闭随机打乱功能。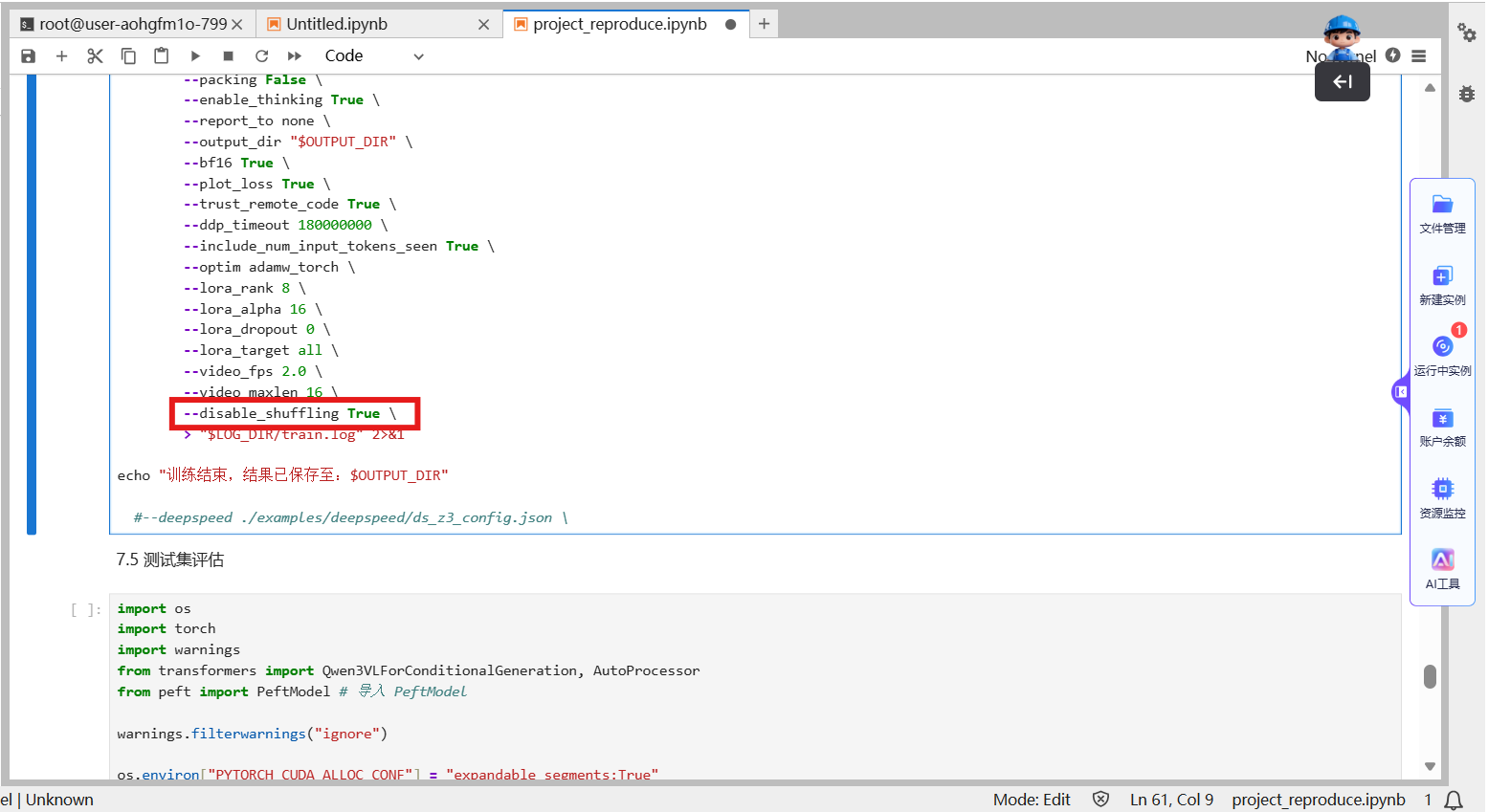## Q9 模型回答胡乱或者重复A模型输出无逻辑胡乱回答、内容重复循环本质是模型输入输出逻辑不匹配或学习过程出现偏差。该问题可能发生在训练前原生模型/ 推理配置问题或训练后微调过程导致的适配偏差需按场景针对性解决核心关联模型类型、模板一致性、过拟合 / 欠拟合三大关键因素。### 场景1训练前就出现胡乱 / 重复回答未微调时**核心原因** 模型本身不具备“遵循指令” 能力或推理模板与模型预期不匹配导致模型无法理解任务逻辑。可尝试下述方法解决#### 1更换 “对齐后” 的模型问题本质未经对齐的base 模型仅具备基础语言能力无 “指令遵循”“对话逻辑” 训练易输出无意义文本或重复内容解决方案替换为instruct/chat 类对齐模型这类模型已通过指令微调能理解 “用户提问→合理回应” 的逻辑#### 2使用与模型匹配的正确模板template问题本质不同模型的prompt 模板格式要求不同模板错误会让模型无法识别输入输出边界导致回答错乱解决方案① 优先使用 LLaMA-Factory 内置模板② 若自定义模板需遵循 “模型训练时的格式”参考模型官方文档确保包含清晰的角色分隔符避坑点不要混合不同模型的模板也不要省略角色标识。#### 3调整推理生成参数若模型和模板正确但仍重复可降低生成温度temperature同时设置 repetition_penalty限制最大生成长度max_new_tokens: 512避免模型无限制重复同一内容。### 场景2训练后出现胡乱 / 重复回答微调后效果倒退核心原因微调过程中“输入输出逻辑传递不一致”或模型学习过度过拟合、学习不足欠拟合导致生成偏差。可尝试下述方法解决#### 1优先检查训练与推理的模板是否完全一致问题本质微调时模型学习的是“特定模板下的输入输出映射”如训练用 “用户提问xxx 模型回答xxx”若推理时改用其他模板如 “xxx”模型无法匹配训练时的学习逻辑会输出混乱内容解决方案① 确保训练配置template 参数与推理配置完全相同② 若忘记训练时的模板可在训练日志中搜索 “template” 关键词或直接复用训练配置文件中的模板参数。#### 2判断是否过拟合针对性调整过拟合表现训练loss 持续下降趋近于 0但推理时回答重复、脱离任务如无论问什么都输出训练数据中的某句话解决方案① 降低训练强度减小 num_train_epochs、调低 learning_rate② 增加正则化③ 扩充数据多样性删除训练数据中的重复样本补充不同场景的有效样本。#### 3排查训练数据质量问题本质训练数据中存在大量重复、无意义、逻辑混乱的内容模型会学到“重复输出” 的错误模式解决方案① 清洗训练数据② 确保数据逻辑一致③ 控制数据长度防止模型学习 “冗长重复” 的表达习惯。#### 4补充微调优化修正模型学习方向若存在“欠拟合”适当增加 num_train_epochs或增大 LoRA 的影响力若使用DPO/ORPO 微调检查偏好数据的质量避免模型学到错误的偏好逻辑。___以上就是 LLaMA-Factory 使用过程中最常见的9个问题及解决方案建议收藏备用如果在实战中遇到其他疑难问题欢迎在评论区留言补充后续会持续更新答疑系列觉得有用的话别忘了点赞、在看、转发给身边需要的朋友呀[点击购买](https://www.lab4ai.cn/course/detail?id7c13e60f6137474eb40f6fd3983c0f46?utm_sourcecsdn_llamafactoryq2)添加课程优惠官了解课程详情## 创作者招募中Lab4AIxLLaMA-Factory邀你共创实战资源想解锁大模型微调实战却愁无算力、缺平台现在机会来了Lab4AI联合LLaMA-Factory启动创作者招募诚邀AI开发者、学生及技术爱好者提交微调实战案例通过审核即享算力补贴与官方证书等共创AI实践新生态。大模型实验室Lab4AI实现算力与实践场景无缝衔接具备充足的H卡算力支持模型复现、训练、推理全流程使用。## Lab4AI大模型实验室还能做什么作为算力驱动的AI实践内容生态社区它不是普通的代码仓库而是集代码、数据、算力与实验平台于一体的平台项目中预装虚拟环境让您彻底告别“环境配置一整天训练报错两小时”的窘境。### 论文板块覆盖从顶刊论文获取Arxiv速递、论文查询、处理翻译、分析、导读、笔记、复现到科研成果转化的全环节为科研人提供一站式工具与资源。### AI课程板块打造“学练结合”模式课程配套可运行实验从模型拼接原理到训练代码实现每一步都有实操支撑有效降低“懂理论不会动手”的学习门槛。LLaMA Factory官方微调课程早鸟价450元开源作者亲授配套300元算力完课证书微调手册答疑社群带您从理论到实践一站式掌握大模型定制化的核心技能。